

One big thing I plan to do is to get started in Bug Bounty, but before becoming the Boba Fett of the code I have to learn the whole methodology of Bug Bounty.

So I will summarize the video "Bug Bounty Hunter Methodology v3" by Jason Haddix (JHaddix) : https://www.youtube.com/watch?v=Qw1nNPiH_Go.
Book resources
If you just getting into bug hunting, these resources are highly recommended :
- The Web Application Hacker's Handbook: Finding and Exploiting Security Flaws
- OWASP Testing Guide v4 (available here)
- Web Hacking 101
- Breaking Into Information Security
- Mastering Modern Web Penetration Testing
When you start a new Bug Bounty programs, one thing that is essential to do first is the reconnaissance of the target.
Discovering IP Space
When you are going after a target, what we want to do is identify both their hosts but also their IP space, so that we have a good reference of their whole internet system.
Here is a few resources that can be use to gather that type of information :
- https://bgp.he.net : the most common one that people use to find an organization's autonomous system number (the IP range that they have registered)
- https://www.arin.net and https://www.ripe.net : to find an organization's registered IPs and domains
- https://www.domainiq.com/reverse_whois : give you anything related to a domain name via reverse whois lookup.
- https://www.shodan.io/ : this site references the result of massive port scans performed on the Internet. It's a gold mine of information for finding organization's internet systems.
Discovering New Targets (Brands & TLDs)
There is some Bug Bounty programs who have wide scope. It means that if you can identify that some infrastructures belong to that organization, they want you to try to hack it. So this section is for discovering new brands and top-level domains.
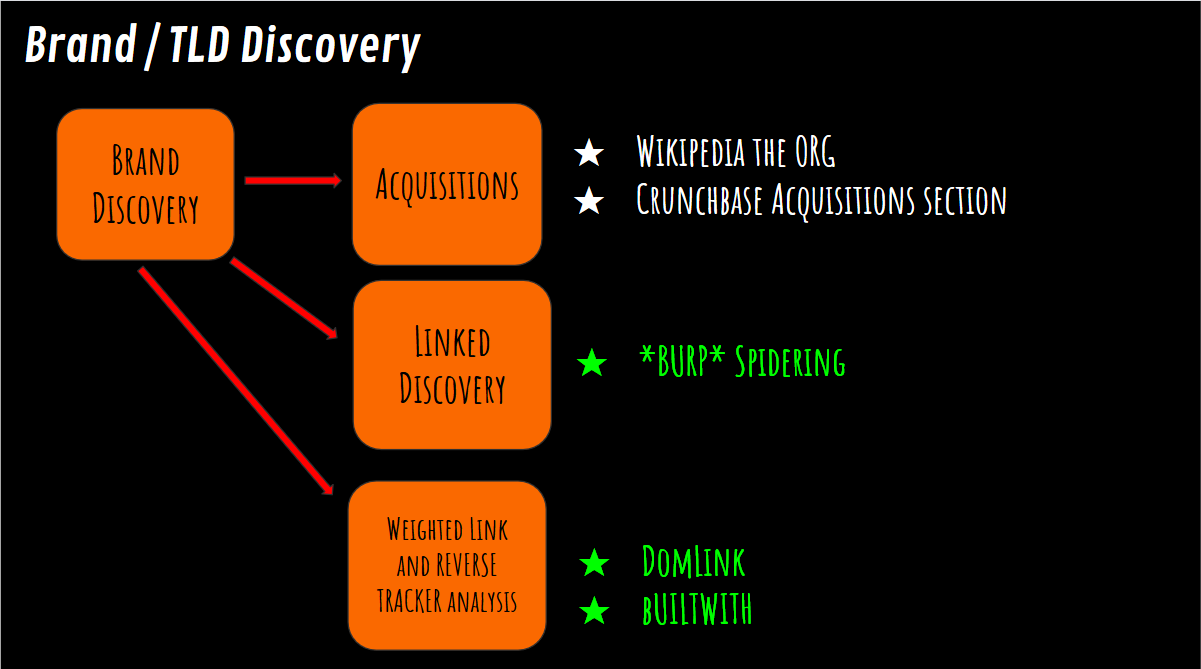
You can use Wikipedia and Crunchbase to search for company acquisitions, when a company acquires another company you imidiately as a Bounty Hunter want to look into see if that acquisition is in scope. These two places are the best to monitor acquisitions, because people use those two sites to trade on stock information and stuff like that, so they stay pretty up-to-date with news around the brand you are looking at.
Another pretty powerful method to discovers new targets, using Burp Suite, is a method called linked discovery :

The principle of this method is to basically visiting your target site itself, and see where it links out to. You can use this method with Burp, you set up a custom scope (keywords) and then you go ahead and browse the site and it will spider all the hosts recursively as you visit them and it will fill up your site tree in Burp. So it will show you anything that matches your keywords that you set in the scope.
Demo video here : https://youtu.be/Qw1nNPiH_Go?t=879
The next method is called DomLink, the idea with this method is to recursively looking at reverse whois programmatically (python script), based on who registered a domain and then creating a link between those domains.
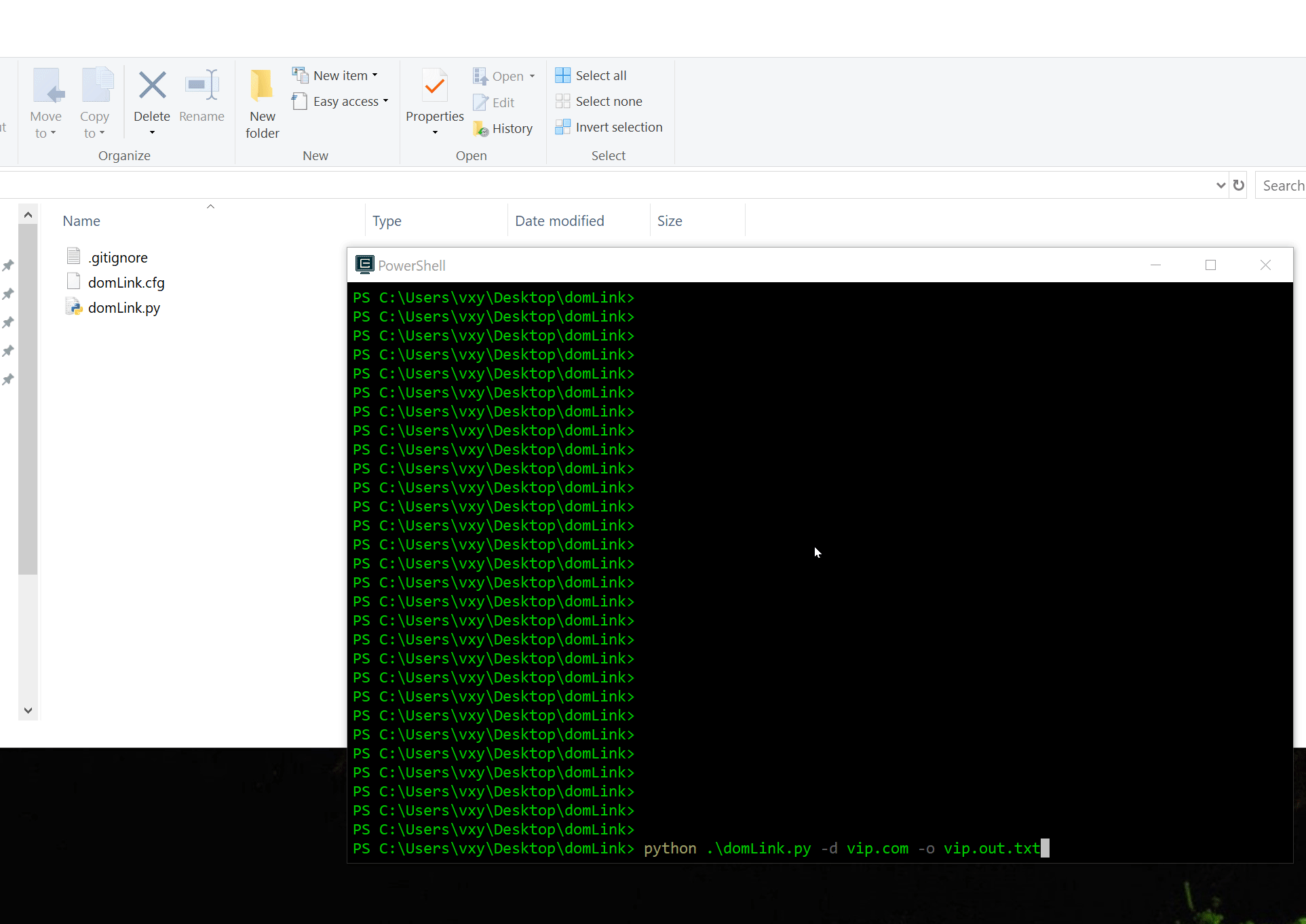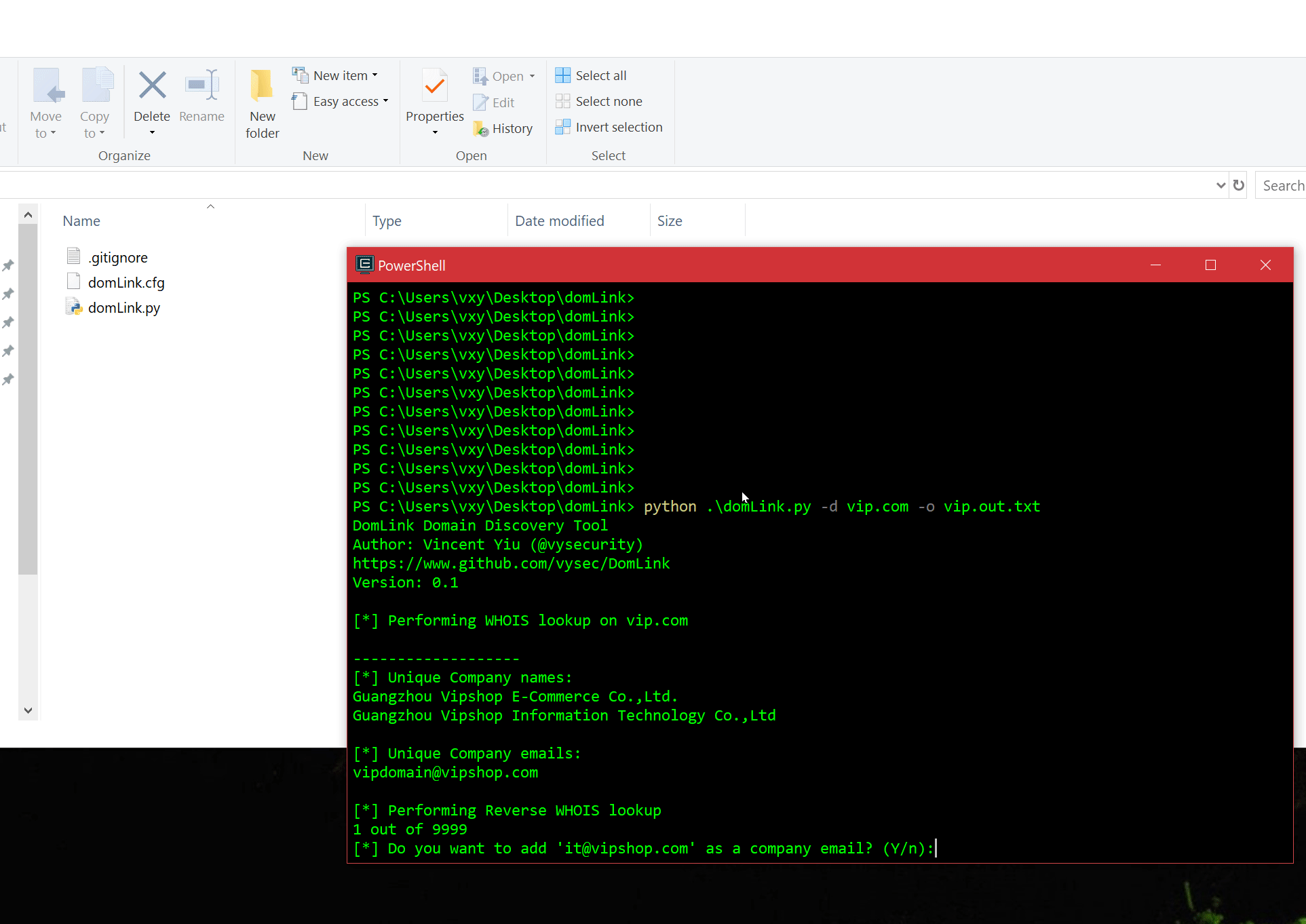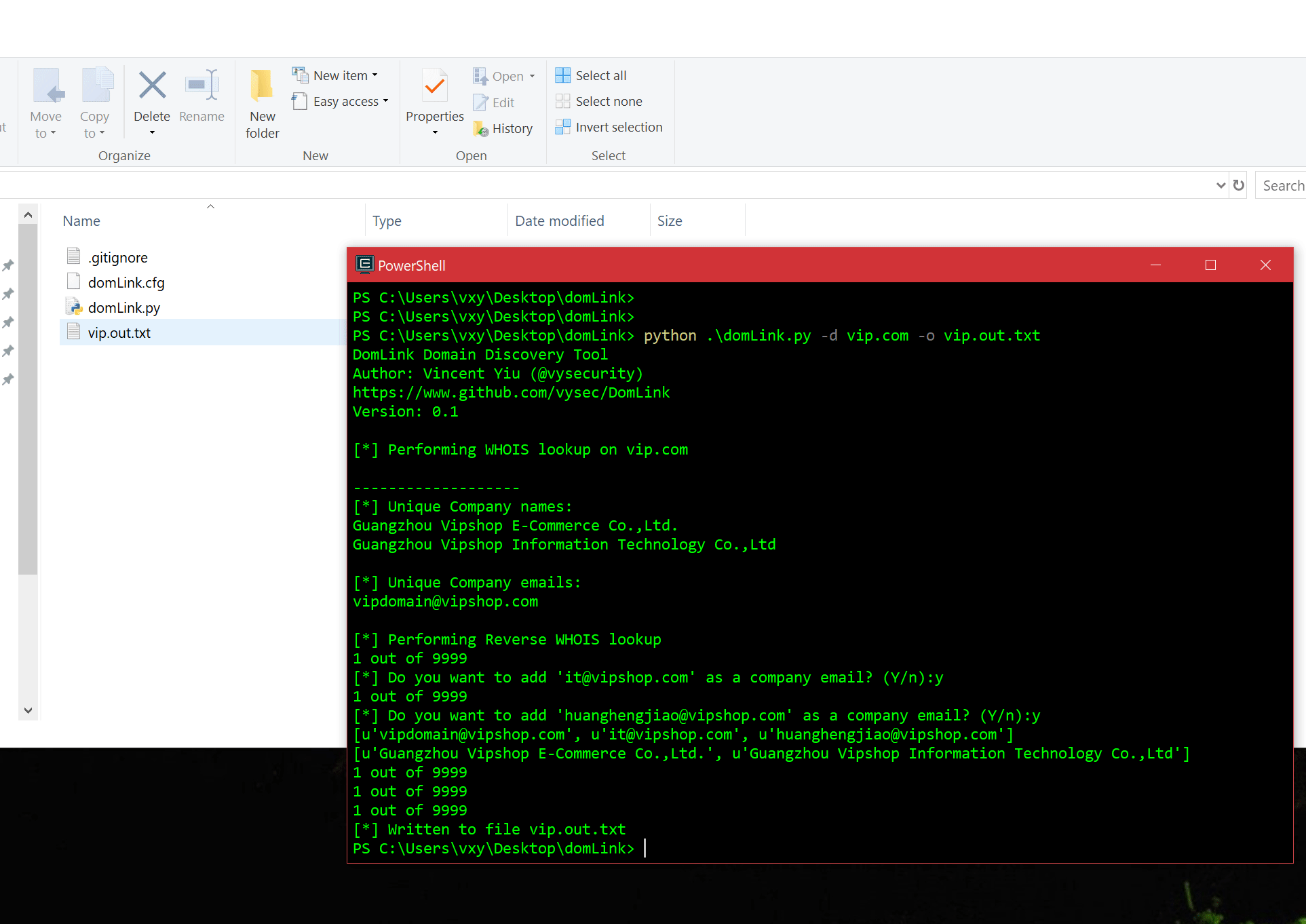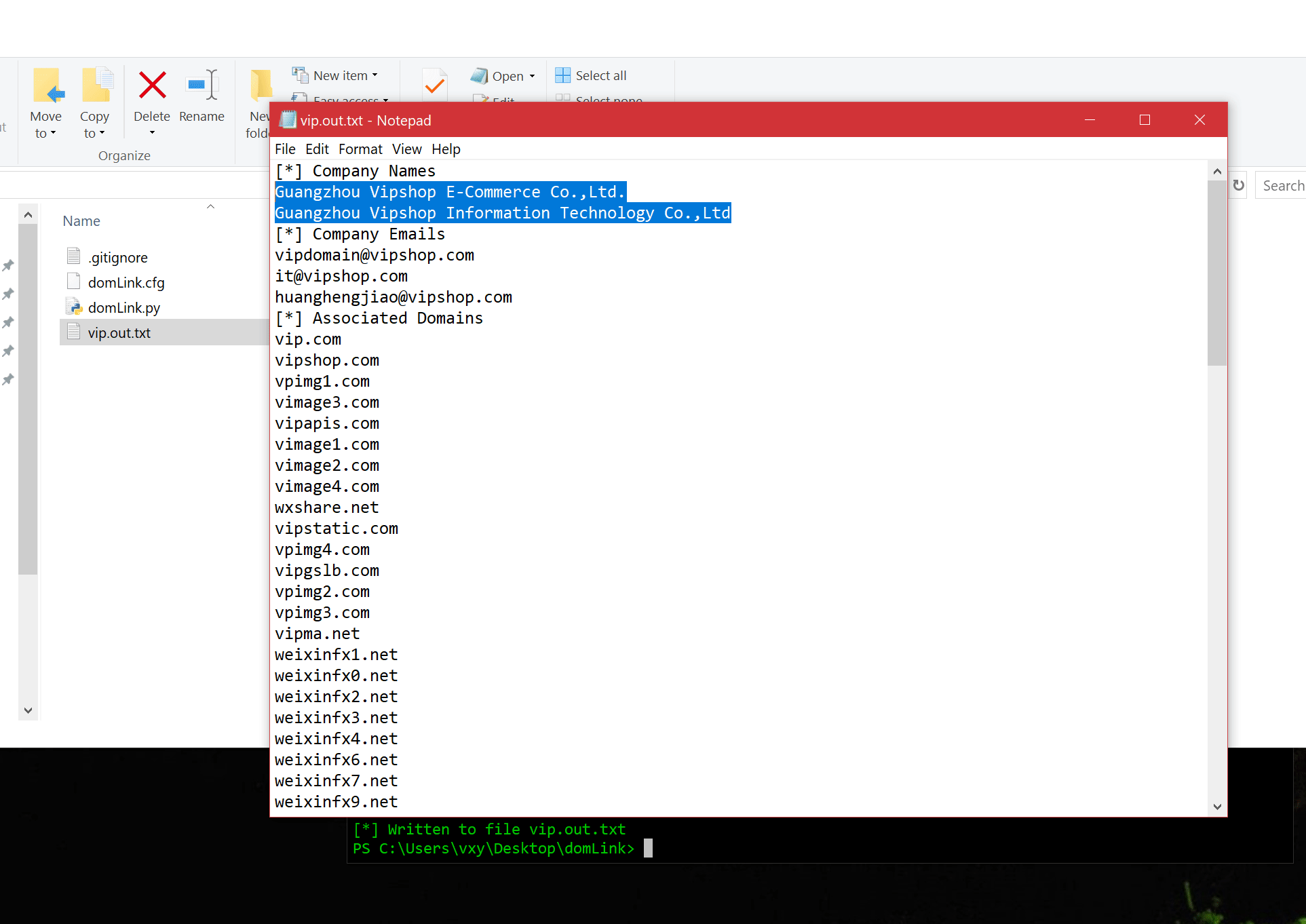
You can find the DomLink tool here : https://github.com/vysecurity/DomLink
Another method is called Builtwith, this site allow you to find out how your target websites are run, what technologies they are using, analytics trackers they use, the type of server software, any frameworks that they use, etc...
There is a Builtwith Browser Extensions available here, with some cool features. There is a feature that allow to basically linking together the relationship of a site based on its analytics trackers, then it will tell you any other domains that it's seen in its databases that use the same code, so you can see related domains that might be related to your target. It can be useful to find sites that are related to your target and in scope, but not explicitly listed.
Some others methods :
- TradeMark in Google : "TESLA @ 2015", "TESLA @ 2019" INURL:TESLA.COM...
Discovering New Targets (Subdomains)
There is two different way of findings subdomains :
- Subdomain scrapping
- Subdomain brute forcing
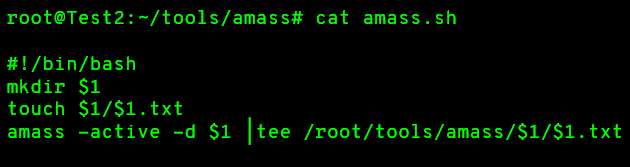
Amass
Amass tool have up to 22 sources that it parses from, and includes a ton of exhilarate features for subdomain enumeration. You can find the Amass tool here : https://github.com/OWASP/Amass
This tool include reverse DNS methods, permutation scanning (when it see a naming nomenclature for a subdomain like Dev-One, it will also check for Dev-Two, Dev-Three, etc...)
You can use this bash script to keep output of your runs, because Amass don't have option to keep output :
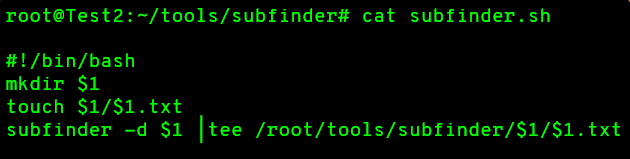
Subfinder
Subfinder tool contains most of the same sources that Amass does, with this tool you can get JSON output, and it also include a brute force section that use a multi resolvers.
You can find Subfinder tool here : https://github.com/projectdiscovery/subfinder
Same as Amass, you can use this bash script to keep output of your runs :
MassDNS
MassDNS is a high-performance DNS stub resolver. MassDNS breaks up your list you try to resolve into small pieces and assigns each one of those pieces to a different DNS resolver. Moreover, It's written in C, so it can run a million line dictionary for brute forcing in about one and a half minutes.
You can find MassDNS tool here : https://github.com/blechschmidt/massdns
Here is a comparison between MassDNS and some others Subdomain Brute Forcing tool :
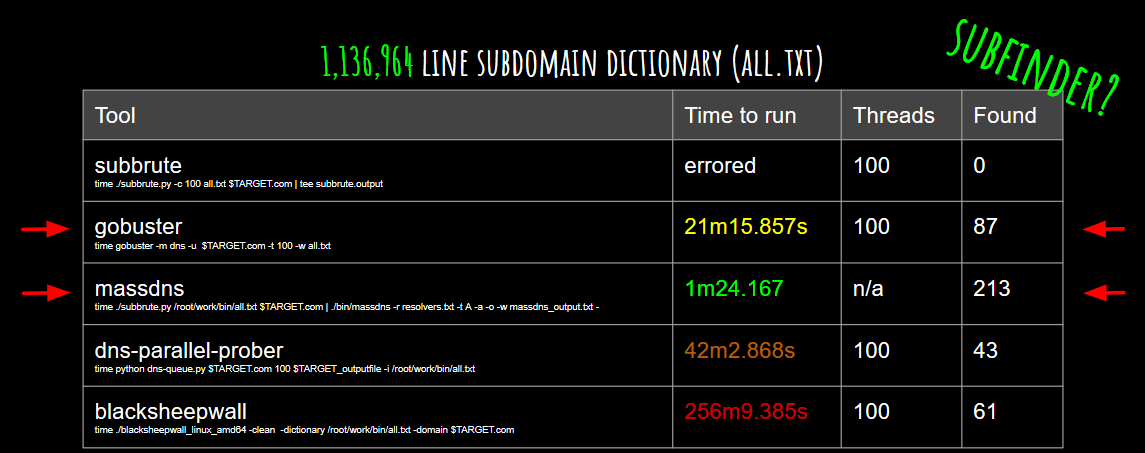
Subfinder use the same method as MassDNS for brute forcing, so it can be as good. And if you are looking for a non-multi resolver tool, GoBuster is the best one for that case.
So with this method of subdomain brute forcing you need a good list of subdomains to brute force from, here you can find some subdomains list : https://github.com/jhaddix/SecLists/tree/master/Discovery/DNS
CommonSpeak and Scans.io
Commonspeak is a wordlist generation tool that leverages public datasets from Google's BigQuery platform.
You can find CommonSpeak tool here : https://github.com/pentester-io/commonspeak
On Scans.io you can find the Internet-Wide Scan Data Repository who is a public archive of research datasets that describe the hosts and sites on the Internet.
These two tools are really useful to build good subdomains list.
Some others methods
Here is some others methods of finding subdomains :
- Doing DNSSEC/NSEC/NSEC3 parsers and doing INSEC Walking or DNSSEC Walking using these utilities : LDNSUTILS, NSEC3WALKER, NSEC3MAP
- Github reconnaissance : search for goodies
- Dorking : ADS Key, Private Policy, TOS, AWS, S3...
Enumerating Targets
So now that we found some top-level domains, and maybe some brands, and we found a whole bunch of subdomains of our target, it's time to get down to individual sites. The first thing we want to do is basically port scanning.
When we talk about port scanning, the first tool that people think of is NMAP, but for any large port scanning NMAP will just take forever. So if you have lot of hosts, doing a full port scanning on all of them will take forever.
MasScan
MasScan is an Internet-scale port scanner. It can scan the entire Internet in under 6 minutes, transmitting 10 million packets per second, from a single machine.
Here is the command to run MasScan :
masscan -p1-65535 -iL $TARGET_LIST --max-rate 100000 -oG $TARGET_OUTPUT
The -oG parameter allow to save the output in a nmap format, so we can re-scan it with nmap version scanning (it's going to be useful for the next tool).
The problem with MasScan is that it won't take DNS name, it will only take IPs, so here is a small shell script to basically run a dig on a domain, it will also strip out a HTTP or HTTPS prefix if you are pulling it out of another tool, and then running MasScan against it :

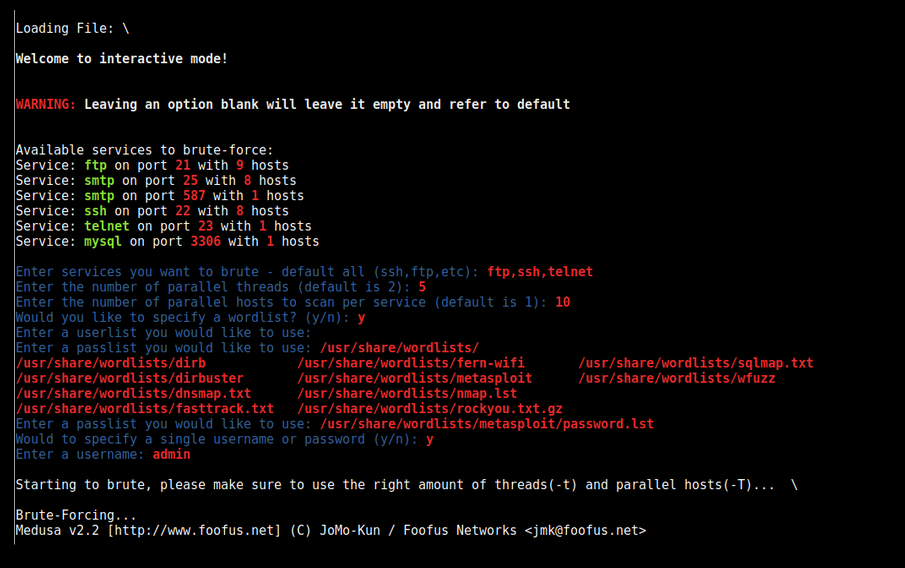
BruteSpray Credential Brute-Force
So once you start doing port scanning across your target there is a number of ports that are going to become interesting to you. You are going to have remote administration protocols like FTP or SSH, and although your bounty is more focused on web, those things are still associated to the servers and if they are vulnerable to either credential brute force or some overflow in the software, it can be interesting.
BruteSpray is a tool that will take our previous scan output (nmap format with version scanning output), and analyse it, and when BruteSpray will encounters one of those remote administration protocols (like FTP or SSH) it will use a small wordlist to try to brute force those hosts (it's using Medusa), with common passwords, default passwords or anonymous login.

This is what BruteSpray look like :
Visual Identification with EyeWitness
We have a ton of top-level domains, and subdomains, that we have scrapped or brute forced across the Internet. But the problem is that they might not be up anymore, and we also have references to them in a format that doesn't tell us what protocol they use (HTTP or HTTPS).
So we are going to use a tool called EyeWitness, it will take a list of domains without a protocol and it will visit each one with a headless browser and take a screenshot of what it sees, and then dump them to a report. It allow us to know which domains are actually redirecting to the same app, which domains are interesting to hack first, which domains are not responding, etc... by looking at the screenshot taken by the tool. The tool will also try both protocol on each domains, so we will know which protocols are used by each domains.
You can find EyeWitness tool here : https://github.com/FortyNorthSecurity/EyeWitness
Here is the command to run EyeWitness :
python EyeWitness.py --prepend-https -f ../domain/tesla.com.lst --all-protocols --headless
Note : if you encounter an a 401/403 error page, basic auth, or domain that seems interesting but is somehow locked down, it can be useful to look at https://archive.org/web/ entries. Sometimes you can find API keys, or URL structure that you can forcefully browse to unprotected content still there. These tools can also be used : https://github.com/tomnomnom/waybackurls and https://github.com/mhmdiaa/waybackunifier.
Stay organized
During your bug hunt, you will gather a lot of information, output from different tools, domains and subdomains list, output from port scans... and this is even more true for large scope bounty. It is therefore very important to stay organized, to take clear notes of all the information collected, and of all the steps carried out.
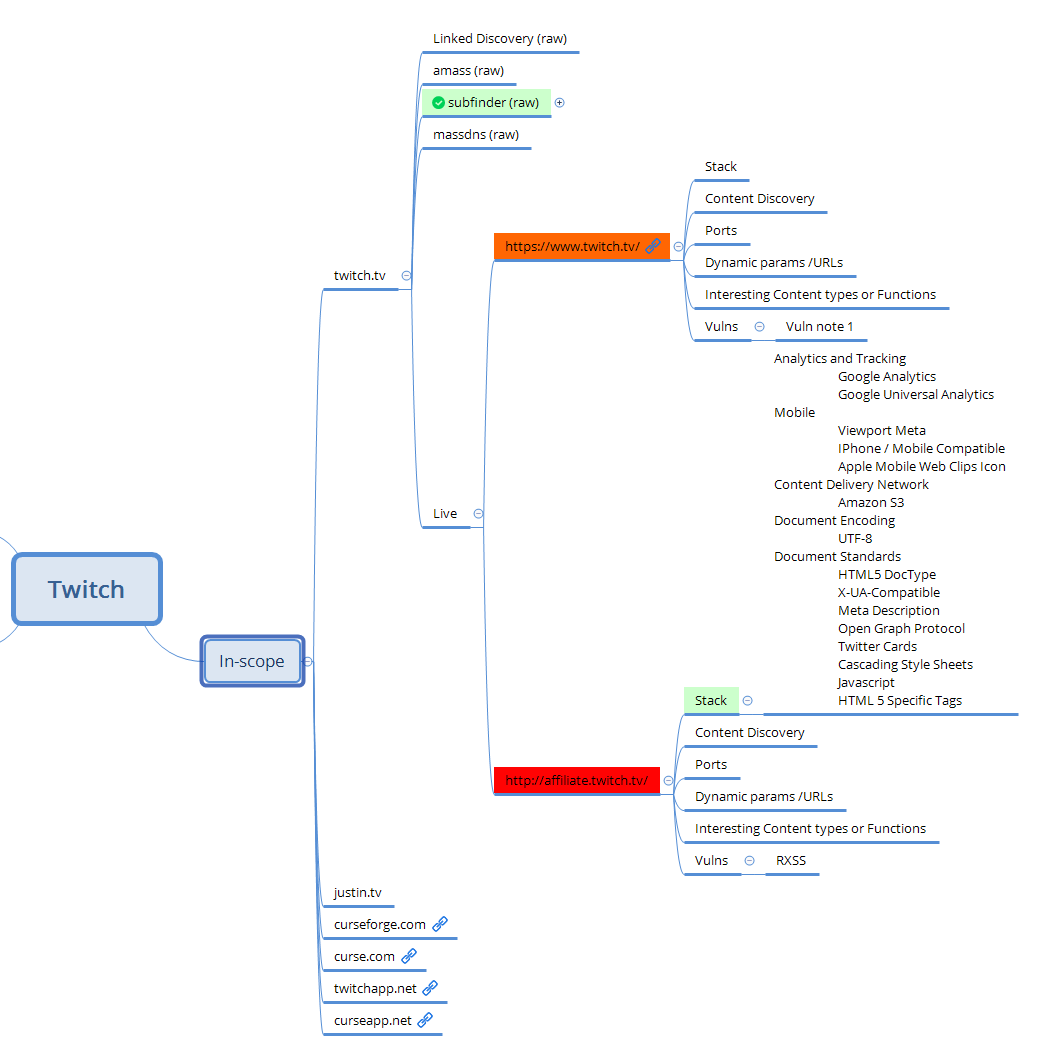
Xmind Organization
To keep track of your progress, it can be useful to use a map mapping software like Xmin Organization. With this tool it's easy to track all your tool used, and track progress across a given bounty.
Platform identification and CVE searching
Now that you have a list of sites you have done port scanning on, it's time to focus on individual site. Here is a list of some tools that may be helpful.
Retire.js
Retire.js is a powerful tool which allow to scan a web app or node app for use of vulnerable JavaScript libraries and/or node modules. This is important to look up at the sites libraries, because "Using Components with Known Vulnerabilities" is now a part of the OWASP Top 10. So Retire.js will tell you if the librairies used by the site are out of date, and if there is an associated vulnerabilities for that version.
You can find Retire.js here : https://retirejs.github.io/retire.js/.
Burp Vulners Scanner
Burp-vulners-scanner is a burp plugin based on https://vulners.com/. Everytime it see a server header that tells the server version number or it find a readme file that as a version number, it will alert you and tell you all the CVEs associated to that version number. There is multiple way it can try to find the version number of the framework or web server. So this scanner is very useful for server software, wordpress installs, basically anything it can pull a version off.
You can find the Burp-vulners-scanner here : https://github.com/vulnersCom/burp-vulners-scanner.
Parsing Javascript
- Zap Ajax Spider : if you switch from Burp to Zap, there is the Ajax Spider plugin, it can be very helpful for parsing web site javascript.

- LinkFinder : this is a python script written to discover endpoints and their parameters in JavaScript files. So it is really useful to find URLs in javascript files.

- JS Parser : another python script using Tornado and JSBeautifier to parse relative URLs from JavaScript files.

Content Discovery
Content discovery is the idea of brute-forcing URL paths,
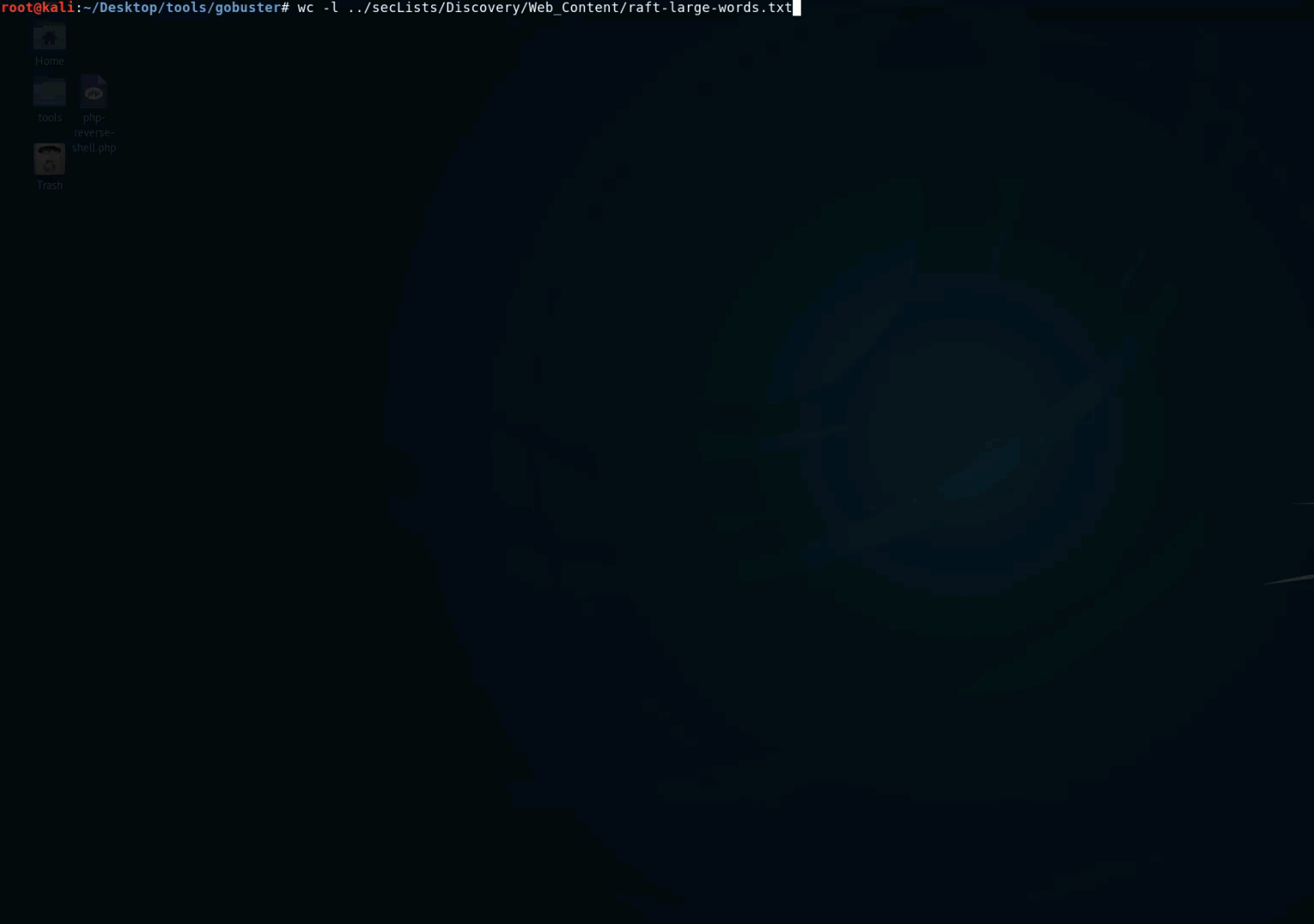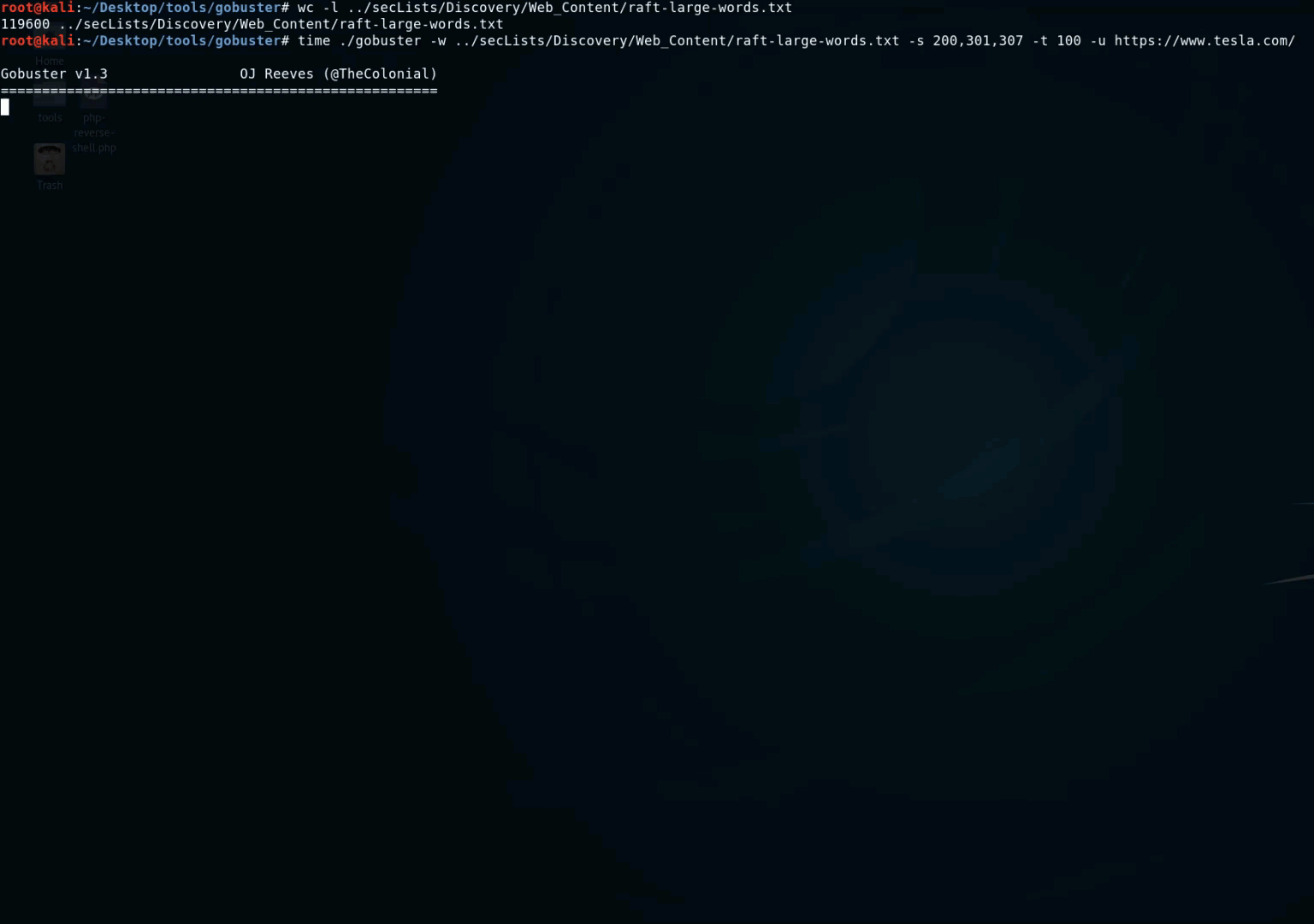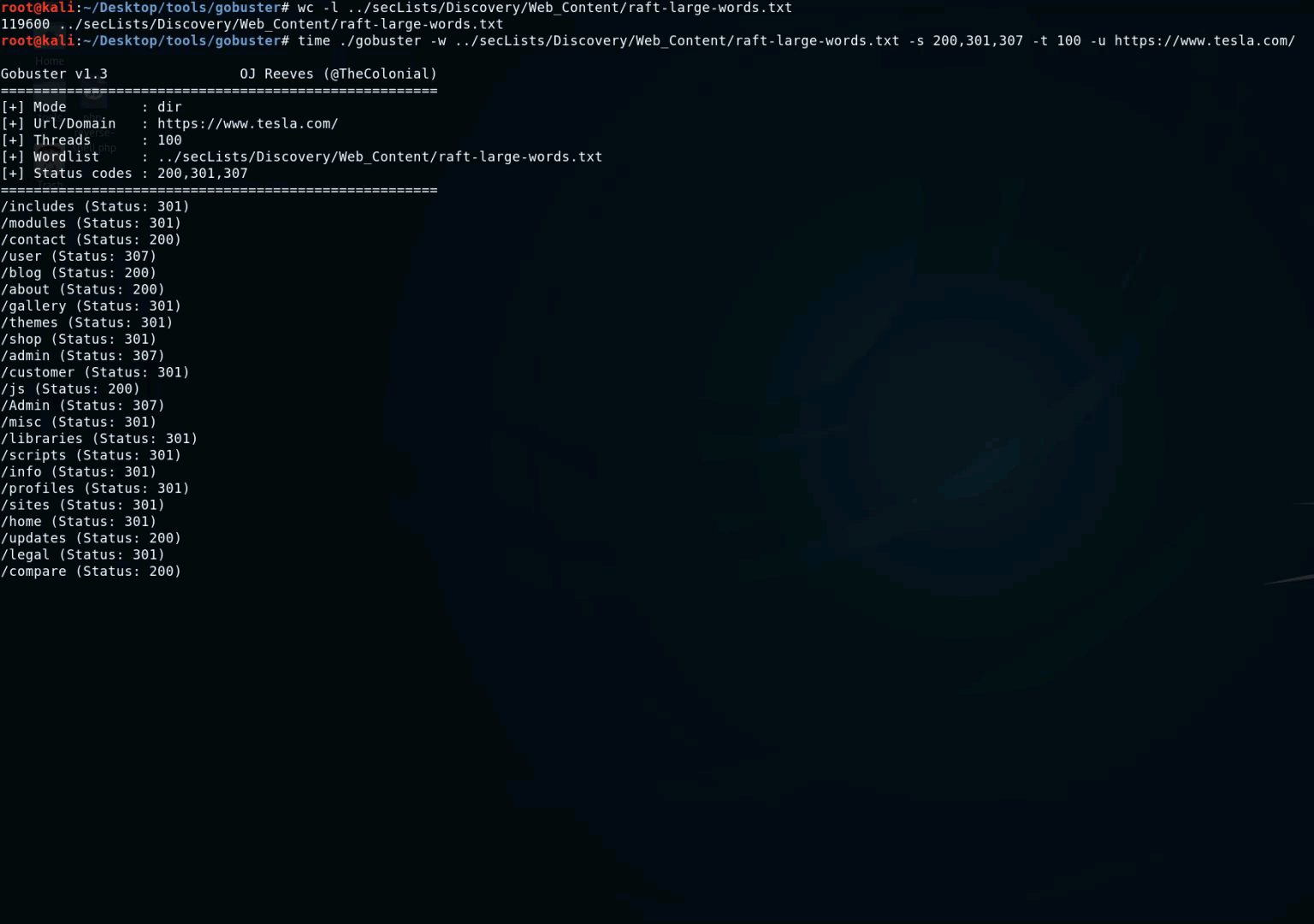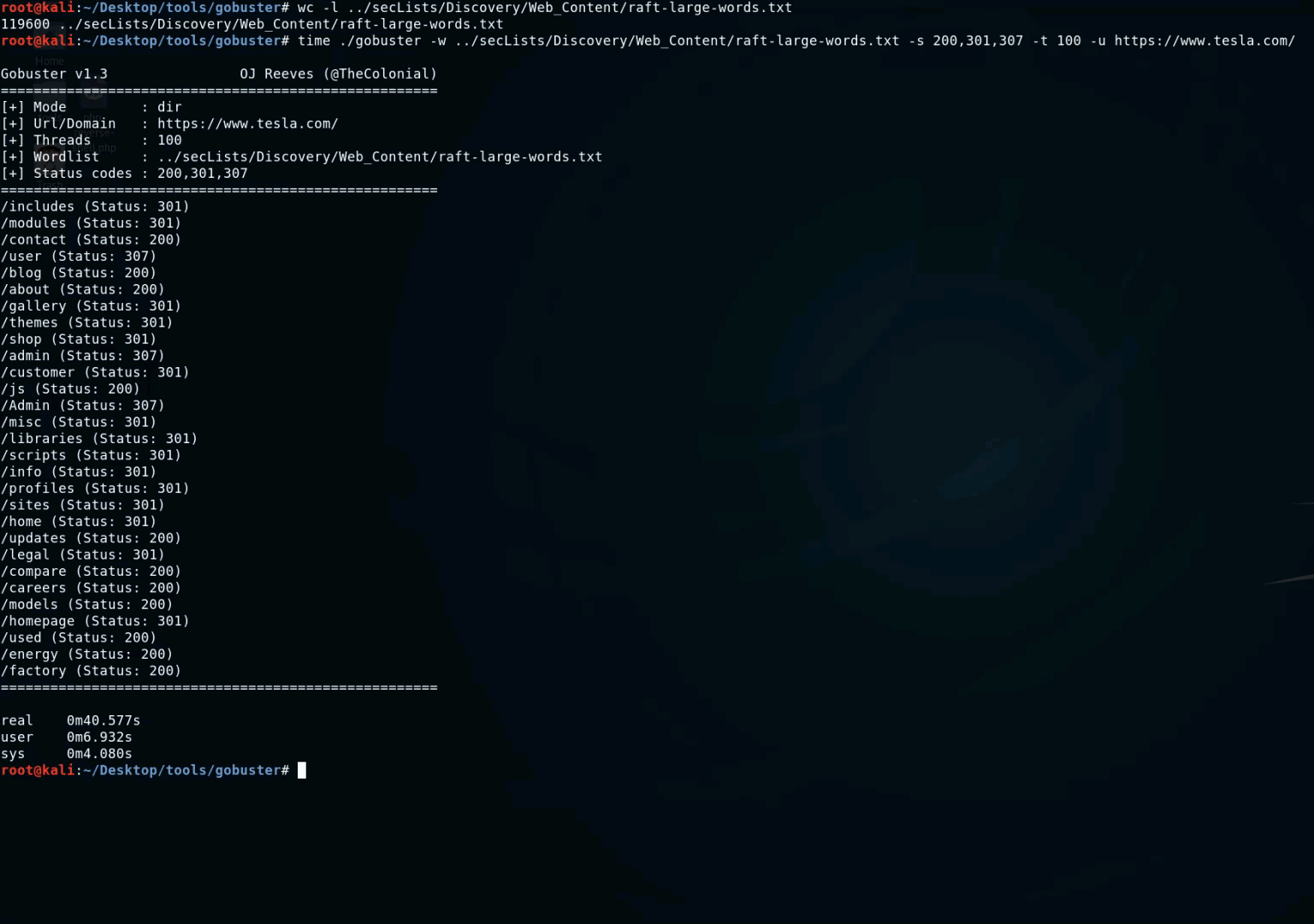
- GoBuster : this is a tool used to brute-force URIs (directories and files) in web sites, DNS subdomains, Virtual Host names on target web servers. It's written in Go and it's really fast. You can use this wordlist with GoBuster : https://gist.github.com/jhaddix/b80ea67d85c13206125806f0828f4d10.

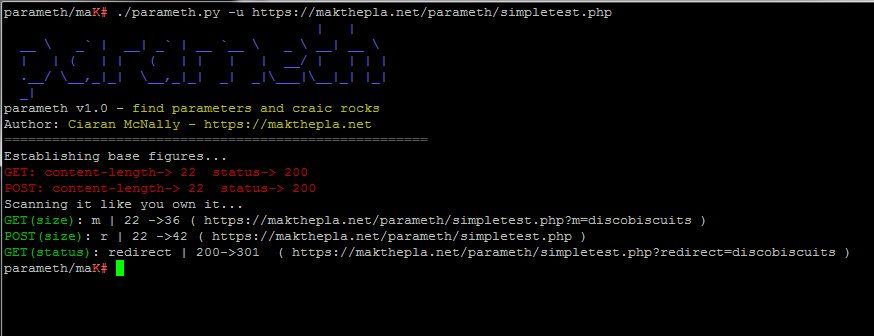
- Parameth : when you have a script and you don't know what parameters it takes, Parameth is the tool to use in this situation.

XSS


S3Scanner

Summary
Here is the whole recon methodology :
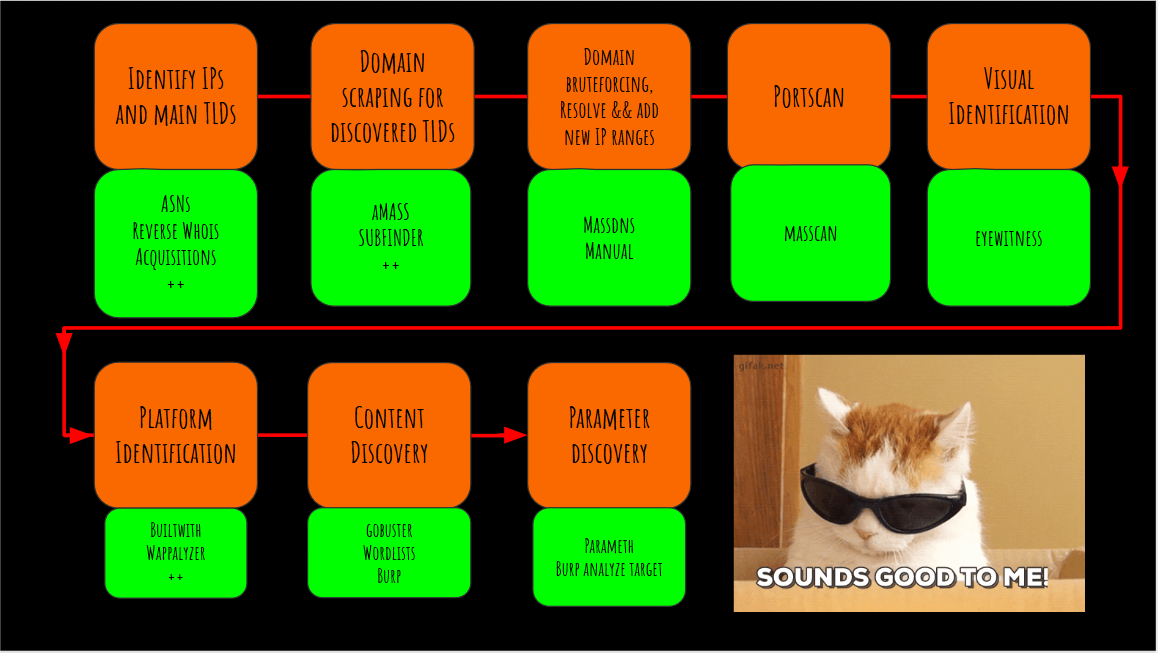
All the credits goes to Jason Haddix, his talk is really useful for understanding how to perform a bug bounty program. I advise everyone to watch his videos to learn more on this subject.
This is the way to become a Bug Bounty Hunter.